■ 台風10号進路図
tenki.jpから台風10号の進路をanimation gifにしてまとめてみた。
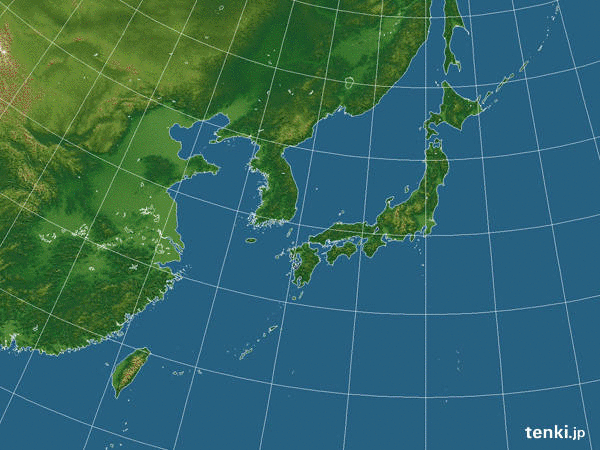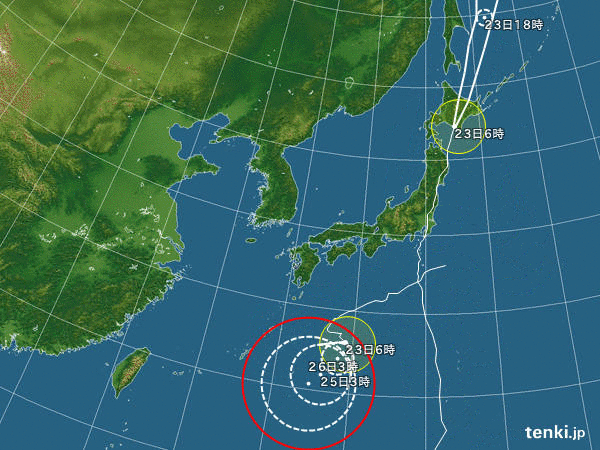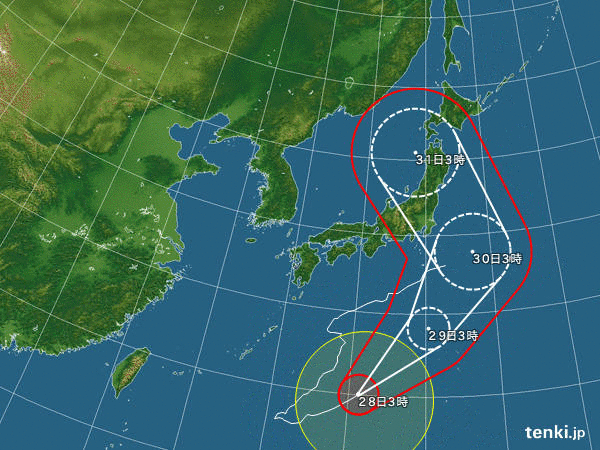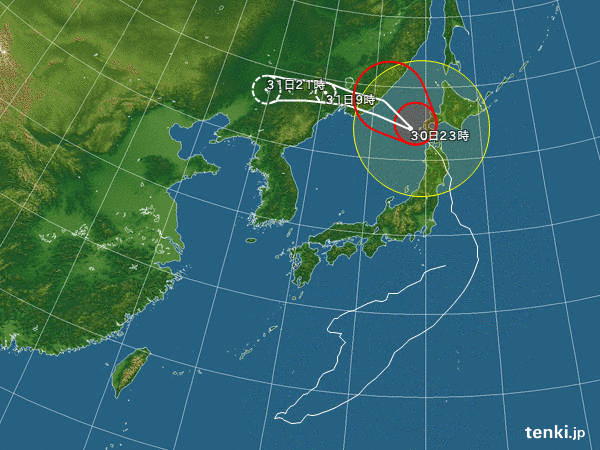
% convert -loop 0 -delay 50 -verbose japan_near_2016-08-{19..30}*.jpg -fuzz 5% -layers optimize typhoon1610.gif
〜2016年8月下旬〜
【問題のみ】第24回◯◯o◯裏番組シェル芸勉強会 – 上田ブログ
8月だから暑いと思い、出掛けるのが面倒という理由で申し込まなかったら、
8月とは思えないほど涼しい日となった。
これのキモは連想配列の初期化にある。
もともとのawkだと配列はdeleteできないが、gawkやmawkだといける。
% cat Q1 | gawk '{for(i=1;i<=NF;i++)a[$i]++;for(k in a)printf "%s ", k":"a[k];print "";delete a}'
玉子:5 卵:1
玉子:3 卵:3
玉子:4 卵:2
玉子:1 卵:5
玉子:2 卵:1
mawkはdelete(a)とは書けない。
gsubは置換した数を返すので、数えるのにも使える。
% cat Q1 | awk '{print "玉子:" gsub("玉子",""), "卵:" gsub("卵","")}'
玉子:5 卵:1
玉子:3 卵:3
玉子:4 卵:2
玉子:1 卵:5
玉子:2 卵:1
まあ、これでいいのかもしれない。
同じことをRubyで。
% cat Q1 | ruby -lne 'print "玉子:", $_.count("玉"), " 卵:", $_.count("卵")'
玉子:5 卵:1
玉子:3 卵:3
玉子:4 卵:2
玉子:1 卵:5
玉子:2 卵:1
count("玉子")としてしまうと、"玉"と"子"の数の合計になるので2倍になってしまう。
そういう方針だとこれでもいいのか。
% cat Q1 | while read a;do echo 玉子:$(echo $a|grep -o .|grep -c 玉) 卵:$(echo $a|grep -o .|grep -c 卵);done 玉子:5 卵:1 玉子:3 卵:3 玉子:4 卵:2 玉子:1 卵:5 玉子:2 卵:1
最後に無理矢理uniq -cを使う方法。
% cat Q1 | while read a; do echo $a | grep -o '玉子\|卵' | sort | uniq -c | xargs -n4; done | awk '{print $2 ":" $1, $4 ":" $3}'
% cat Q1 | xargs -L1 sh -c 'echo "$@" | grep -o "玉子\|卵" | sort | uniq -c' - | xargs -n4 | awk '{print $2 ":" $1, $4 ":" $3}'
% cat Q1 | sed 's/.*/echo & | grep -o "玉子\\|卵" | sort | uniq -c/' | sh | xargs -n4 | awk '{print $2 ":" $1, $4 ":" $3}
sedで変換してshに食わせるほうがちょっと短い。
sortせずにuniqする。awkでは有名なテクニック。
% grep -o . Q2 | awk '!a[$0]++' へ の も じ % grep -o . Q2 | awk '!a[$0]++' | paste -sd '' へのもじ
といわけで縦を横にする方法をいくつか。
tr -d '\n'では最後の改行も消えてちょっと見栄えが悪い。
そこでpaste -sd ''となる。
次にORS=""で改行が消えることを利用する方法。
% grep -o . Q2 | awk '!a[$0]++' ORS= | xargs へのもじ
xargsで改行を追加している。awk 1でもok。
% grep -o . Q2 | awk '!a[$0]++' ORS= | awk 1 へのもじ
xargsでひとまとめにして、空白を削除。
% grep -o . Q2 | awk '!a[$0]++' | xargs | tr -d ' ' へのもじ
コマンド置換を利用して、空白削除。
% echo $(grep -o . Q2 | awk '!a[$0]++') | tr -d ' ' へのもじ
Rubyで。Rubyは-F ""とはできないので小細工が必要。
% ruby -F\| -pale '$_=$F.uniq*""' Q2 へのもじ
nlで元の順番を保存してsort -uする方法。
% grep -o . Q2 | nl | sort -uk2,2 | sort -n | cut -f2 | paste -sd '' へのもじ
sedで。
% sed -r ':;s/((.).*)\2/\1/;t' Q2 へのもじ
最後にPerlで。なにやってるのかよくわからないと思うが、おれもよくわからない。
% perl -Mopen=:utf8 -CIO -pe 's/./$&x~$`!~~$&/ge' Q2 へのもじ
$`がマッチ文字列の前の部分なのでそこにマッチしたものがなければx1して、
あったらx0して消してるという感じがするが、それだと~が多すぎる気がする。
基本的には模範解答と同じ。
% sort Q3 | awk 'l!=$1{print "%%";l=$1};1'; echo %%
%%
キム タオル
キム ワイプ
%%
金 正男
金 正日
金 日成
%%
あまり別解を思いつかなかったので、jq 1.5で。
% jq -srR 'split("\n")|group_by(split(" ")[0])|"%%",.[1][],"%%",.[2][],"%%"' Q3
%%
キム ワイプ
キム タオル
%%
金 日成
金 正日
金 正男
%%
なんか順番違うけど気にしない。
意外にわかりやすい。
例のバグっぽい仕様を考慮して1.4でも動くようにすると、こんな感じ。
% jq -s -r -R 'split("\n")|group_by(split(" ")[0])|reverse|"%%",.[1][],"%%",.[0][],"%%"' Q3
%%
キム ワイプ
キム タオル
%%
金 日成
金 正日
金 正男
%%
xlsxファイルはxmlファイル等をzipで圧縮したものなので、
結局はxmlファイルを扱うことになる。
% unzip -p Q4/Q4.xlsx xl/worksheets/sheet1.xml | awk '/A1/{print $NF}' FS='<v>' RS='</v>'
114514
xmlやhtmlで処理するときの定番。
debian系にはxlsxファイルをCSVに変換するコマンドが存在する。
xlsx2csvとまさにそのままの名前だが、これを使うとお手軽。
% xlsx2csv Q4/Q4.xlsx 114514,シェル芸バイブ 危険シェル芸,ドラゴン曲線 キュアエンジニア,素数 エクシェル芸,変態シェル芸
あとはもうふつうにawkで。
% xlsx2csv Q4/Q4.xlsx | awk -F, 'NR==1{print $1}'
114514
% xlsx2csv Q4/Q4.xlsx | awk -F, 'NR==4{print $1}'
エクシェル芸
sedでxを置き換えるよりは題意の通り代入したほうが簡単。
% echo x=2 | cat - Q5 | bc -l 6 2.50000000000000000000 8 % cat <(<<<x=2) Q5 | bc -l 6 2.50000000000000000000 8
というわけでecho 2で始めても同じ方針でいける。
% echo 2 | sed 's/^/x=/;r Q5' | bc -l 6 2.50000000000000000000 8
tenki.jpから台風10号の進路をanimation gifにしてまとめてみた。
% convert -loop 0 -delay 50 -verbose japan_near_2016-08-{19..30}*.jpg -fuzz 5% -layers optimize typhoon1610.gif